


今天凌晨,Google DeepMind 发布了新一代开源模型 Gemma 4:以 30B 左右的参数,逼近其他头部开源模型
Gemma 是 Google 的开源模型系列,和闭源旗舰 Gemini 共享底层技术,权重完全公开,任何人可以下载、修改、部署。上一代 Gemma 3 是 2025 年 3 月发的,到这次更新整整一年。在这一年里国内几家开源模型已经迭代了好几轮,Google 在开源赛道的存在感越来越弱
这次一口气放出四款模型,分别是 2B、4B、26B 和 31B,覆盖了手机到工作站全场景。许可证从 Google 自有协议换成了 Apache 2.0
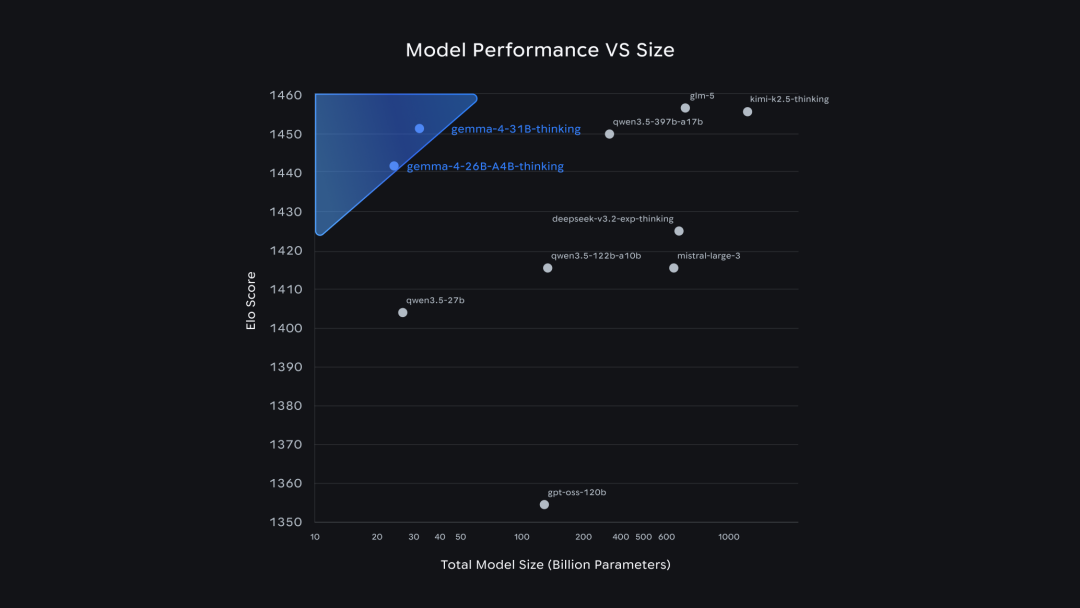
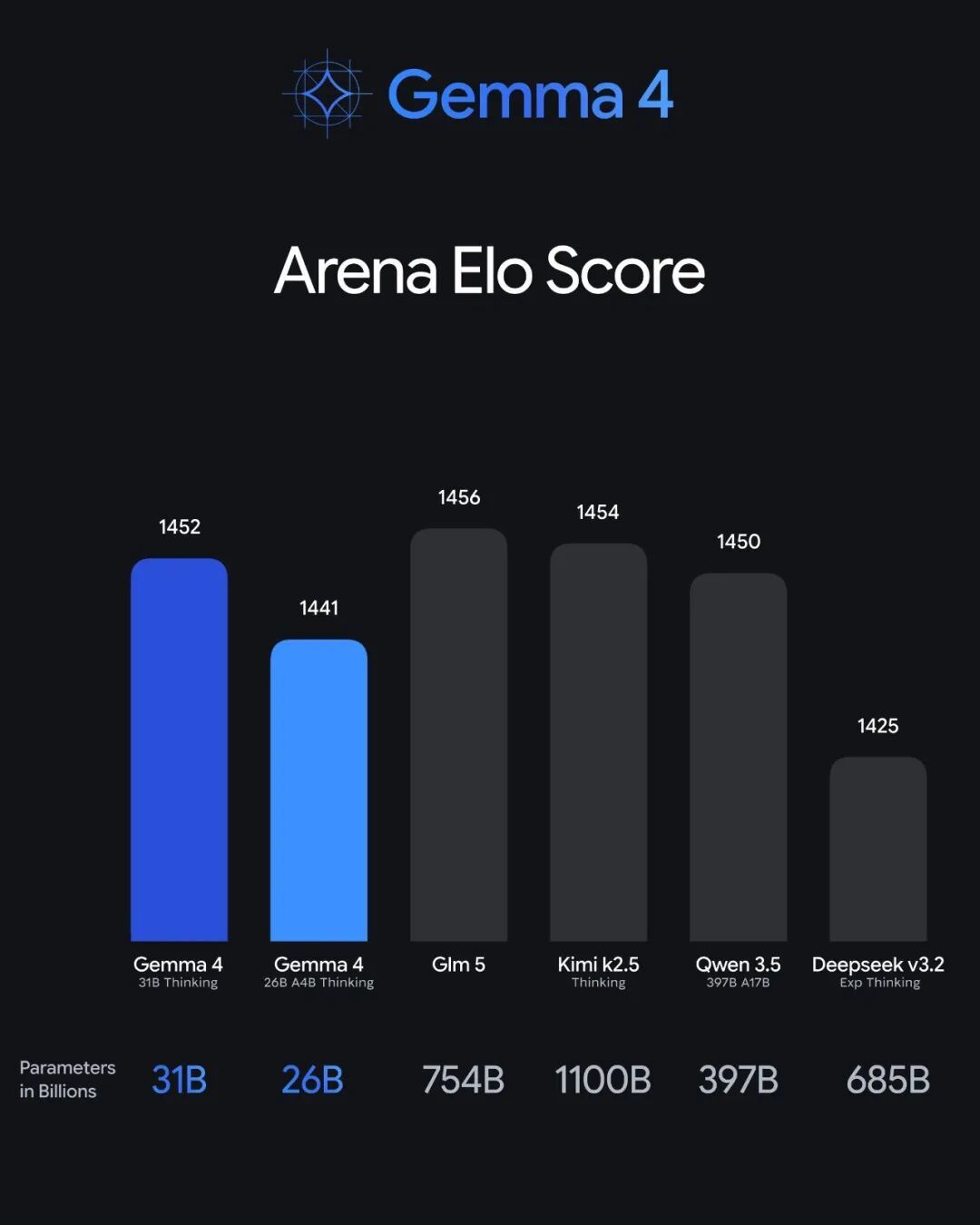
Gemma 4 在 Arena AI 开源排行榜的 Elo 评分 vs 参数量,31B 排第三,26B MoE 排第六
四款模型
Gemma 4 发布了四个版本,分大模型组和小模型组
31B Dense:310 亿参数全激活,60 层,256K 上下文。追求质量上限,Arena AI 开源排行榜第三。未量化 bfloat16 权重一张 80GB H100 就能装下,量化后消费级显卡也能跑
26B A4B MoE:252 亿总参数、38 亿激活参数,MoE 架构(128 个专家,每次激活 8 个加 1 个共享),30 层,256K 上下文。推理速度接近 4B 模型,质量远超 4B 水平。排行榜第六
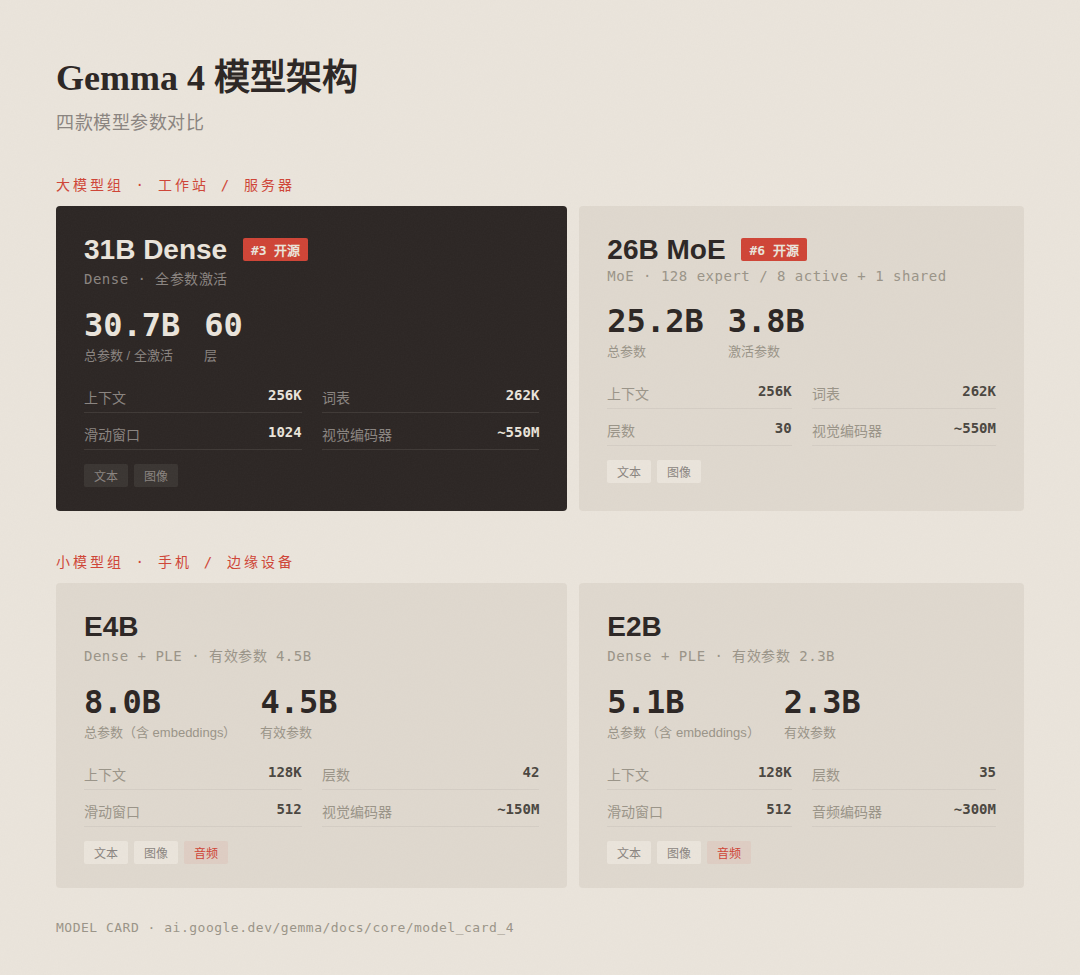
四款模型架构参数对比
E4B:80 亿总参数、45 亿有效参数,42 层,128K 上下文。名字里的 E 是 Effective 的缩写,小模型用了 Per-Layer Embeddings 技术,有效参数远小于总参数
E2B:51 亿总参数、23 亿有效参数,35 层,128K 上下文。据官方说法,在部分设备上内存占用可以压到 1.5GB 以下

官方的四款模型能力对比
所有模型都支持图像和视频输入,支持 140 多种语言
各模型均为多模态,小模型支持语音输入,大模型反而不支持
E2B 和 E4B 各自带了一个约 3 亿参数的音频编码器,可以做语音识别和语音翻译(最长 30 秒)。大模型没有音频能力。从产品逻辑看,手机端语音是刚需,工作站场景下不是
Google 和 Pixel 团队、高通、联发科合作优化了端侧部署。E2B 和 E4B 可以在手机、树莓派、NVIDIA Jetson Orin Nano 上完全离线运行
成绩
先说结论:相比上一代 Gemma 3 27B,多个核心指标的提升是代际级别的
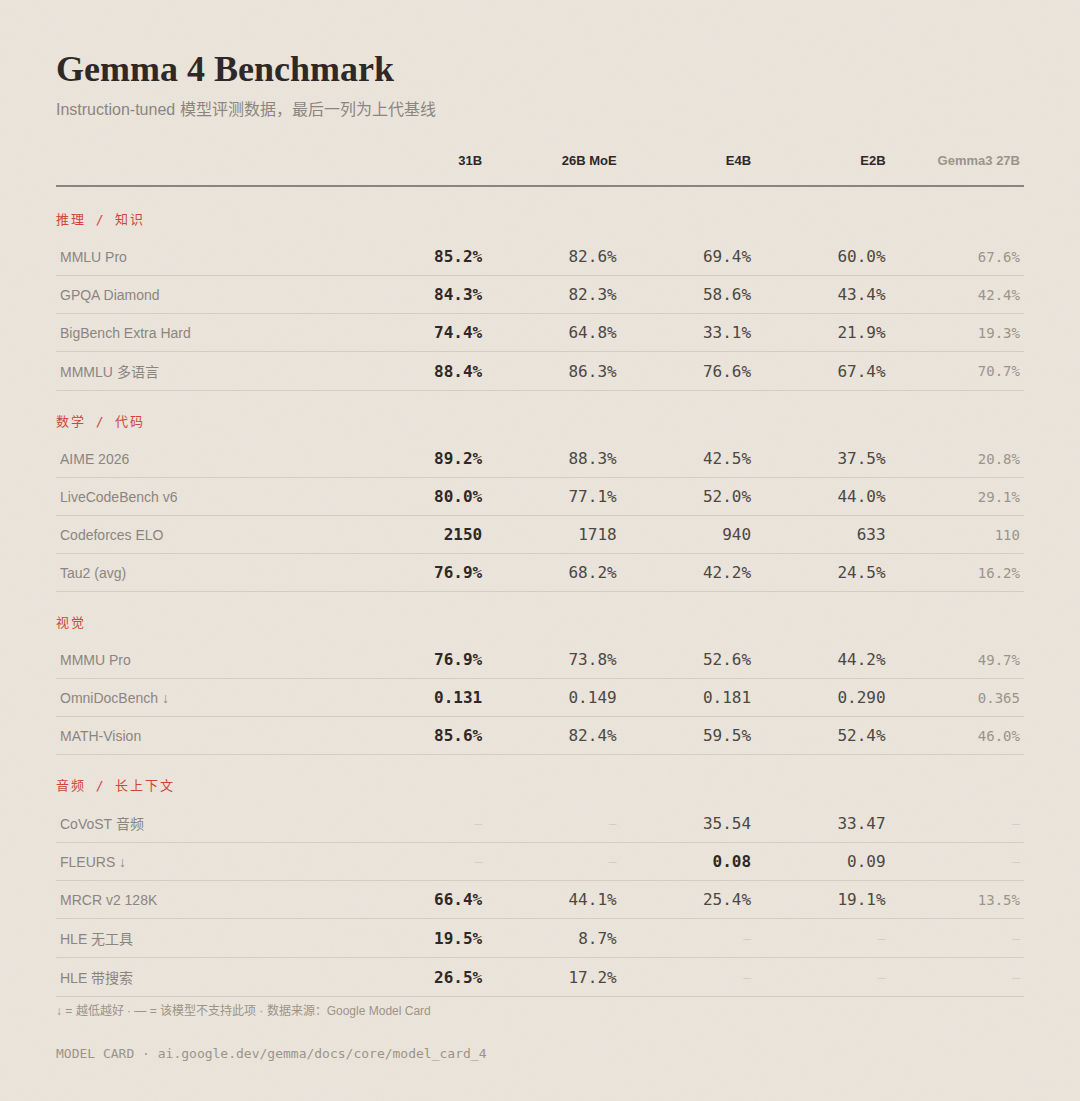
Gemma 4 完整 Benchmark 数据,最后一列为 Gemma 3 27B 基线
数学:AIME 2026 竞赛测试,31B 拿到 89.2%,Gemma 3 27B 是 20.8%
代码:Codeforces ELO 从 110 拉到 2150。LiveCodeBench v6 从 29.1% 到 80.0%。代码是这次进步最大的方向
综合推理:GPQA Diamond(研究生级科学问答)从 42.4% 到 84.3%。MMLU Pro 从 67.6% 到 85.2%
视觉:MMMU Pro 从 49.7% 到 76.9%。文档 OCR(OmniDocBench)从 0.365 到 0.131
长上下文:MRCR v2 128K 从 13.5% 到 66.4%。长上下文此前是 Gemma 的短板,这次补回来了
多语言:MMMLU 从 70.7% 到 88.4%。原生训练了 140 多种语言
26B MoE 和 31B 在大部分指标上只差 2 到 5 个百分点,但推理速度快得多。延迟敏感的场景下 26B MoE 性价比更高
E4B 的 MMLU Pro 69.4%%,有效参数只有 45 亿,接近上一代 27B 的水平
核心能力
推理和思考。四款模型都内置了可开关的思考模式,开启后模型先输出内部推理再给答案。数学、逻辑、多步骤规划类任务效果好很多,和 Gemini 的 thinking 能力同源
Agent 工作流。原生支持函数调用和结构化 JSON 输出,可以让模型调用外部工具和 API。Google 同步发布了 Agent Development Kit(ADK),一个开源的 Agent 框架。端侧 E2B/E4B 也能跑 Agent,Google AI Edge Gallery 里已有示范应用
代码生成。支持离线写代码。Codeforces ELO 2150、LiveCodeBench 80.0%,在代码补全和生成场景里是可用的
多模态理解。所有模型都能处理图片和视频(视频按帧处理,最长 60 秒)。图片支持可变分辨率和宽高比,视觉 token 预算可手动配置(70 到 1120 五档),低预算换速度,高预算换精度。OCR、文档解析、图表理解是重点场景
长文档。大模型 256K 上下文,小模型 128K。架构上用混合注意力机制(局部滑动窗口 + 全局注意力交替),全局层用统一 KV 和 Proportional RoPE 优化长上下文的内存占用
多语言。原生训练 140 多种语言,MMMLU 88.4%
Apache 2.0
之前 Gemma 1/2/3 用的都是 Google 自己的许可协议,虽然允许商用但有附加条款。这次直接换成了 Apache 2.0,开源社区最认可的商业友好型许可证之一。开发者可以自由修改、分发、商用,没有用户量门槛
Hugging Face 联合创始人 Clément Delangue 评价这是一个重大里程碑。从 Gemma 系列自身看(三代自定义协议 → Apache 2.0),这是一个明确的转向
Google 用许可证的选择回答了一个讨论了两年的问题:大厂做开源到底有多大诚意
开源赛道的竞争者
Arena AI 开源排行榜上,Gemma 4 31B 排第三、26B MoE 排第六。排在前面的主要是国内的开源模型
目前开源赛道的主要竞争者是 DeepSeek(V3.2 在用,V4 即将发布)、通义千问 Qwen3.5、智谱 GLM-5.1、MiniMax M2.5、月之暗面 Kimi K2.5。这几家在今年春节前后密集发布了新版本,参数量从几百亿到上千亿不等,在推理、代码、Agent 等方向各有侧重
Gemma 4 最大只有 31B,参数量的天花板是一个限制。但 Gemma 4 在端侧部署的工程完整度上做得最深:和高通、联发科的芯片级合作,和 Android 生态的原生打通,加上 Apache 2.0 的合规便利,这些是它的差异化
训练数据截止到 2025 年 1 月,且没有公开训练数据的具体组成
本文转自:凤凰网科技
原文地址: https://tech.ifeng.com/c/8rzTWHnsC92
小同爱分享1 个月前
命没了还有轮回,钱没了,死都不甘心。 - 小同爱分享
小同爱分享4 个月前
疫情,就是让人抑郁,又没了感情。 - 小同爱分享