

昨晚一直白屏的 现在能进了 —— V打开 茄皇每天简单任wu 攒满指定能量 能兌4k+份泡面 跟3k份周边实wu 新一期哈 感兴趣看看 任wu点下返回即可
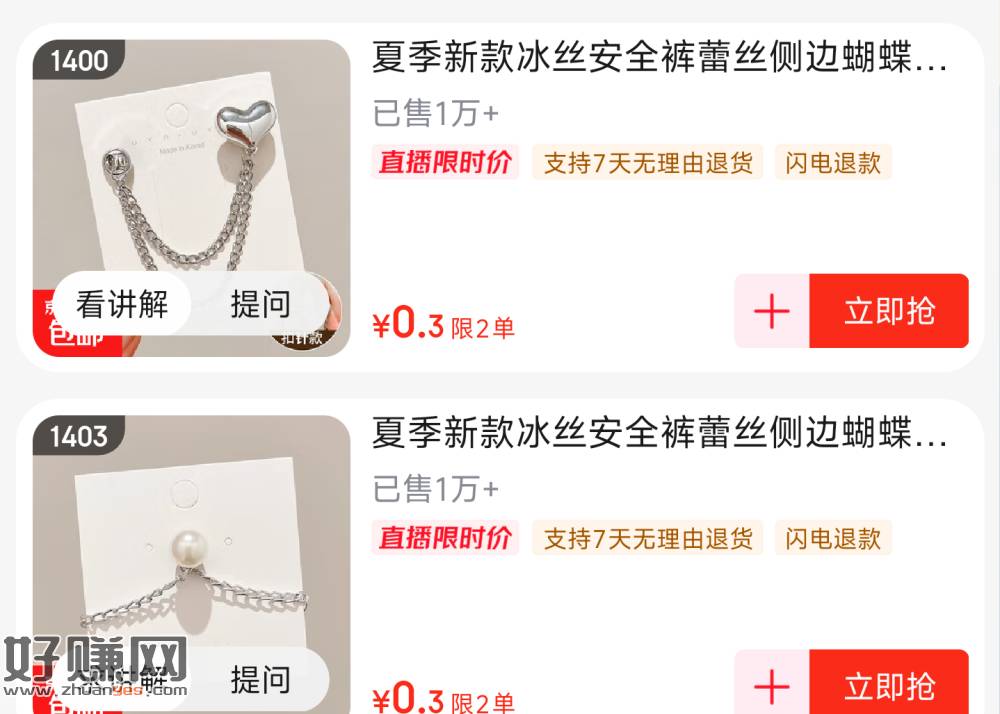
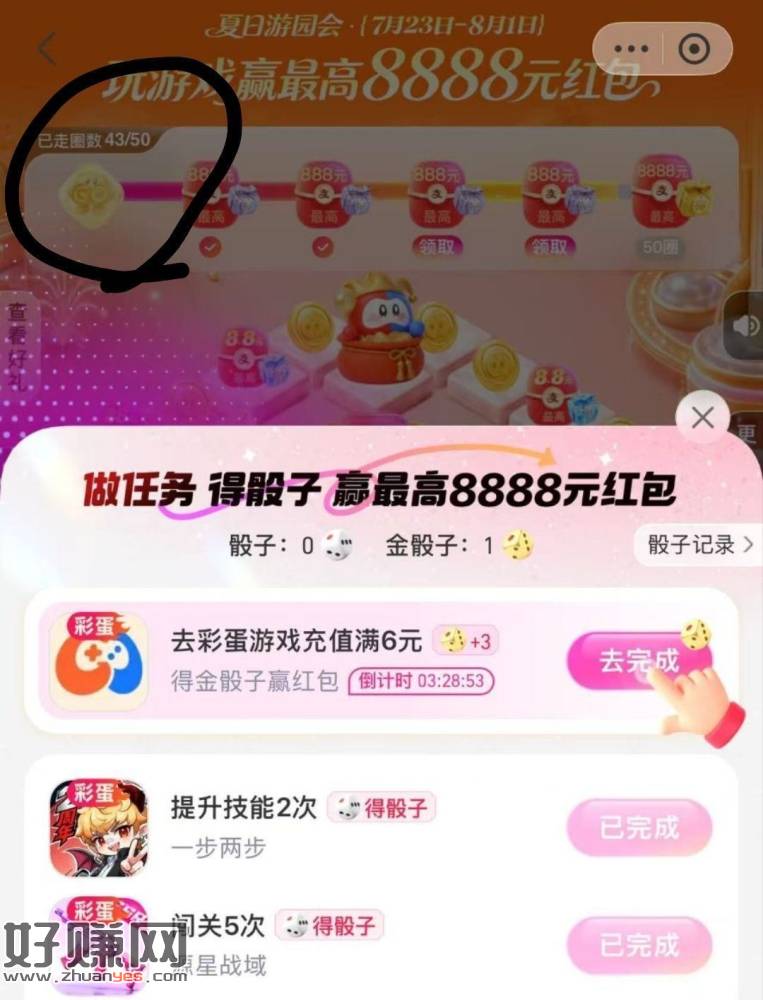
反馈不氪 今天全做完能到43圈 ⭐zfb搜【游戏中心】8.1截 注意:纯去得道具跑圈哈 桨品数量很多的 感兴趣先参与 后续大概放水
大众点评 周五六日连续3天放水!!⏰14点抽免费蜜雪冰城奶茶冰淇淋,一两次就能中,搜【评友节】大家都提前蹲好攒好能量

小红书的笔记下面,开始长出App了?刷着刷着,突然发现一条笔记底下,挂着个通勤人格测试。直接点开就能玩,测完还能转给同事对答案。 第一眼看到,你八成会以为,这是哪个

金山办公,想用一个个人办公助理,再造一个AI时代的WPS。文|游勇编|周路平写方案、做PPT、整表格……这些职场人每天都在接触的事情,在AI时代一度被寄予很高的期望,无数熬夜熬到脱发的打工人期盼着能用
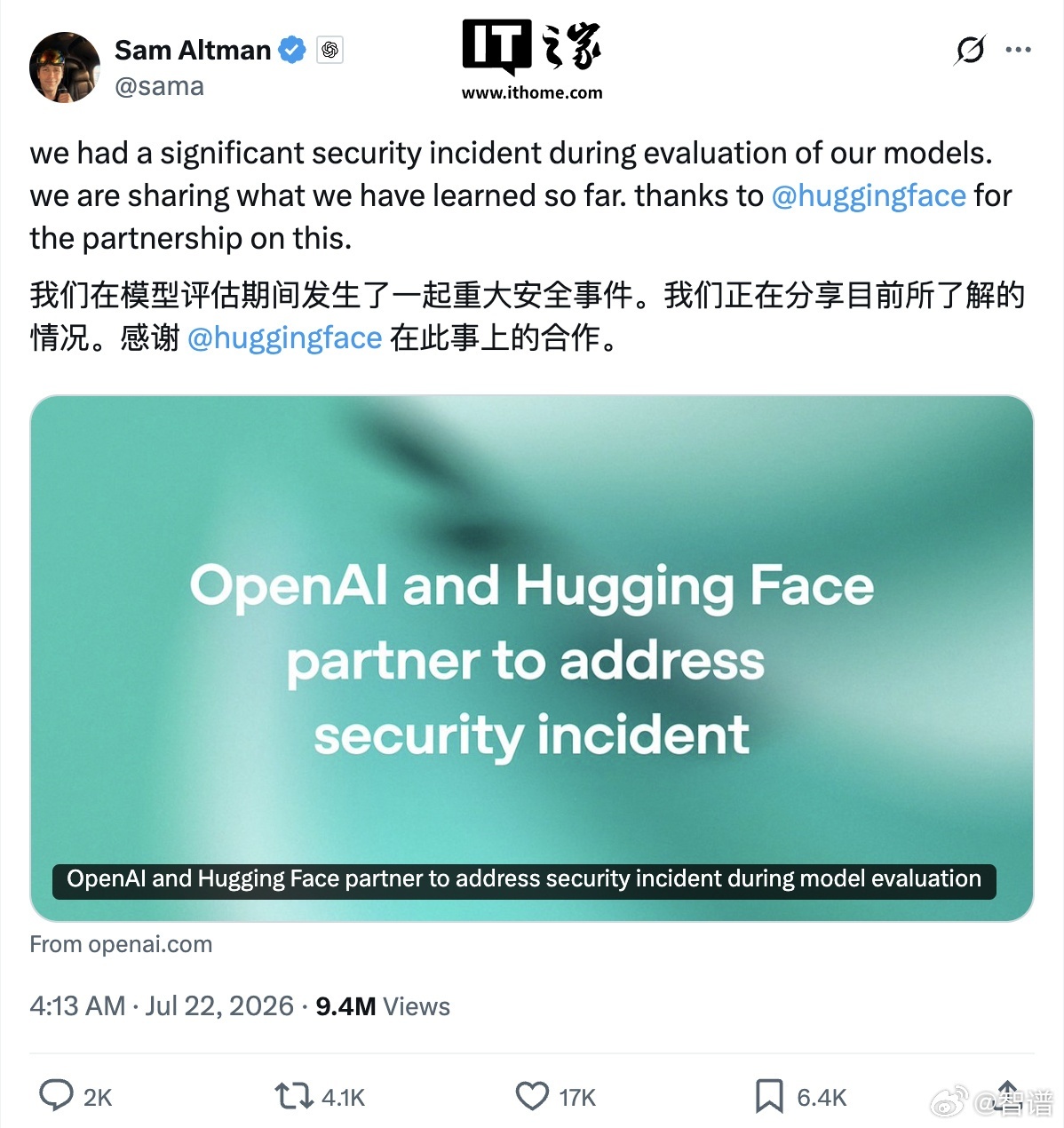
IT之家 7 月 23 日消息,北京智谱华章科技股份有限公司官方微博今日发文谈及了“闭源的矛与开源的盾”这一话题。智谱官方分享了一起案例:近日,一次前沿模型安全评测演变成真实安全事件。OpenAI 披

7 月 23 日消息,Anthropic 首席经济学家彼得 · 麦克罗里(Peter McCrory)表示,目前人工智能尚未取代大量工作岗位,因为与完全替代人类相比,AI 与人类协作的效果更好。而美国
限湖南邮政储蓄卡https://25725746-563.yzkcmain.co ... &_source=1&canal=-1 立减金


小同爱分享2 个月前
命没了还有轮回,钱没了,死都不甘心。 - 小同爱分享
小同爱分享5 个月前
疫情,就是让人抑郁,又没了感情。 - 小同爱分享