


作者 | 冬梅
今天凌晨,喜欢闷声做大事的 DeepSeek 再次发布重大技术成果,在其 GitHub 官方仓库开源了新论文与模块 Engram,论文题为 “Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models”, 梁文锋再次出现在合著者名单中。

与传统的大模型架构相比,该方法提出了一种新的“查—算分离”机制,通过引入可扩展的查找记忆结构,在等参数、等算力条件下显著提升模型在知识调用、推理、代码、数学等任务上的表现。代码与论文全文均已开源。
论文地址:
https://file.tonglife.net/images/59/3e8acbaa547d26c358f0e9bb95f01b.jpg
代码地址:https://file.tonglife.net/images/e4/ffd6985e9642d84da91e964387350b.jpg
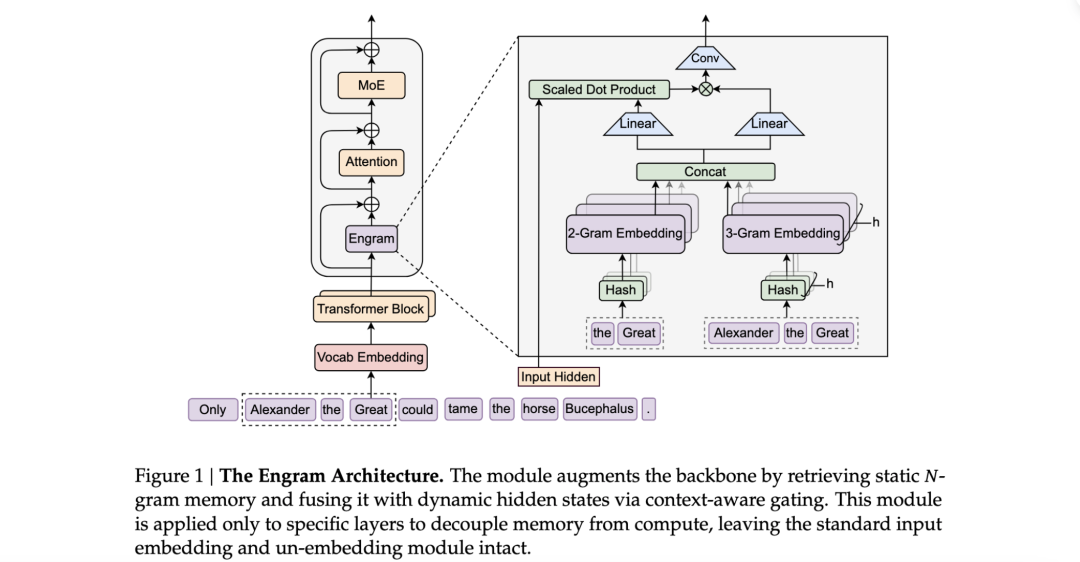
这种查和算分离的 Engram 新方法的整体架构如下图所示:
01
为什么需要 Engram?
那么,我们为什么需要 Engram ?
目前主流的大语言模型架构依然基于 Transformer 和 Mixture-of-Experts(MoE) 结构。MoE 是目前推进参数规模和能力扩展的关键技术之一,通过动态路由机制,只激活部分参数以降低计算成本,同时在任务容量方面实现大规模扩展。DeepSeek 自家系列模型(如 DeepSeek V2、DeepSeek V3 等)也采用了先进的 MoE 方法进行扩展训练。
但在这些传统的 Transformer 架构(无论是 Dense 还是 MoE)中,模型的参数实际上承担着两种截然不同的角色:
事实性记忆(Memorization): 存储海量的知识事实。例如,“法国的首都是哪里?”、“世界最高的山脉是哪座”等。这类信息相对死板,更多依赖于“查表”式的检索。
逻辑推理与计算(Calculation): 负责复杂的逻辑链条、多步推理和情境理解。例如,“根据这段代码的逻辑推导可能的 Bug”、“解析一段复杂的哲学论证”。
目前的大语言模型倾向于将这两者混在一起。当你试图让模型记住更多知识时,你不得不增加参数量。而在传统的 Dense 模型中,参数量增加意味着前向传播时的计算量(FLOPs)也会同步激增。MoE 架构虽然通过稀疏激活解决了“算力随参数同步爆炸”的问题,但 DeepSeek 研究发现,MoE 专家在处理“死记硬背”的任务时依然不够高效。
神经网络本质上是连续的数学变换,用高昂的矩阵运算去模拟简单的“查表检索”,本身就是一种极大的浪费。DeepSeek 的 Engram 正是为了打破这一困境——“该查表的查表,该算的算”。
02
Engram 的核心思想与架构
聚焦到问题本身,Engram 方法为什么能解决上述问题?
“Engram”一词源自神经科学,意为“记忆痕迹”,它是一个 可扩展、可查找的记忆模块,用于语言模型在推理过程中过去可能已经见过的模式或片段。
Engram 的核心技术之一是 现代化的哈希 N-Gram 嵌入(Modernized Hashed N-gram Embeddings)。
传统方式: 模型通过多层自注意力(Self-Attention)和 MLP 层的非线性变换,反复提取输入文本中的特征。
Engram 方式: 它对输入的 Token 序列进行 N-Gram(连续 N 个词)切片,并利用哈希算法将这些片段映射到一个巨大的、可学习的查找表(Lookup Table)中。
由于采用哈希索引,这种查找是 确定性且 O(1) 时间复杂度 的。这意味着无论模型存储了多少万亿个记忆片段,检索的速度几乎是恒定的,且算力消耗极低。
O (1) 的含义是: 一次查找的耗时是常数级的,与 N-gram 表的规模无关。
也就是说,这种设计本质上将一部分“记忆职责”从深度神经计算中卸载出来(例如序列模式、固定知识段的识别与回填),使得模型既拥有活跃神经通道(例如 Transformer + MoE)处理复杂计算,也有静态记忆通道高效处理固定模式,这就是所谓的 “稀疏性的新轴”(a new axis of sparsity)。
简单来说就是 MoE 负责:“计算密集”神经推理与复杂组合功能、Engram 负责:“记忆查找”固定模式以及模式重建,两者协同构成一个更高效的整体架构。
此外,它还具备条件记忆(Conditional Memory)。与简单的静态查找表不同,Engram 是“条件化”的。它会根据当前上下文的隐向量(Hidden States)来决定提取哪些记忆。
在架构设计上,Engram 模块位于 Transformer 层的早期阶段。它负责“模式重构(Pattern Reconstruction)”,即在计算层(MoE 或 Dense)开始干活之前,先把相关的背景事实和历史模式检索出来,作为“素材”喂给后续的逻辑层。
它与 MoE(Mixture of Experts)的关系是怎样的?
论文特别指出:Engram 提供了一个新的稀疏性轴,与 MoE 的条件计算不同,它通过条件查找提供静态记忆容量。下面图表中从目标、计算方式、优化方向和作用位置四个维度解释了 Engram 和 MoE 的区别。
| 维度 | MoE | Engram |
|---|---|---|
目标 |
条件激活神经专家 |
条件触发静态记忆查找 |
计算方式 |
无极 dense 计算 / 激活部分专家 |
O(1) 查表 |
优化方向 |
降低活跃神经计算量 |
减少神经计算重建已知模式 |
作用位置 |
深层推理 |
早期模式重建 / 记忆检索 |
最后,DeepSeek 将 Engram 与 MoE 结合,形成了一个双系统:
Engram 模块: 负责海量知识点的“存储与快速检索”。
MoE 专家: 摆脱了沉重的记忆负担,全身心投入到“逻辑推理与合成”中。
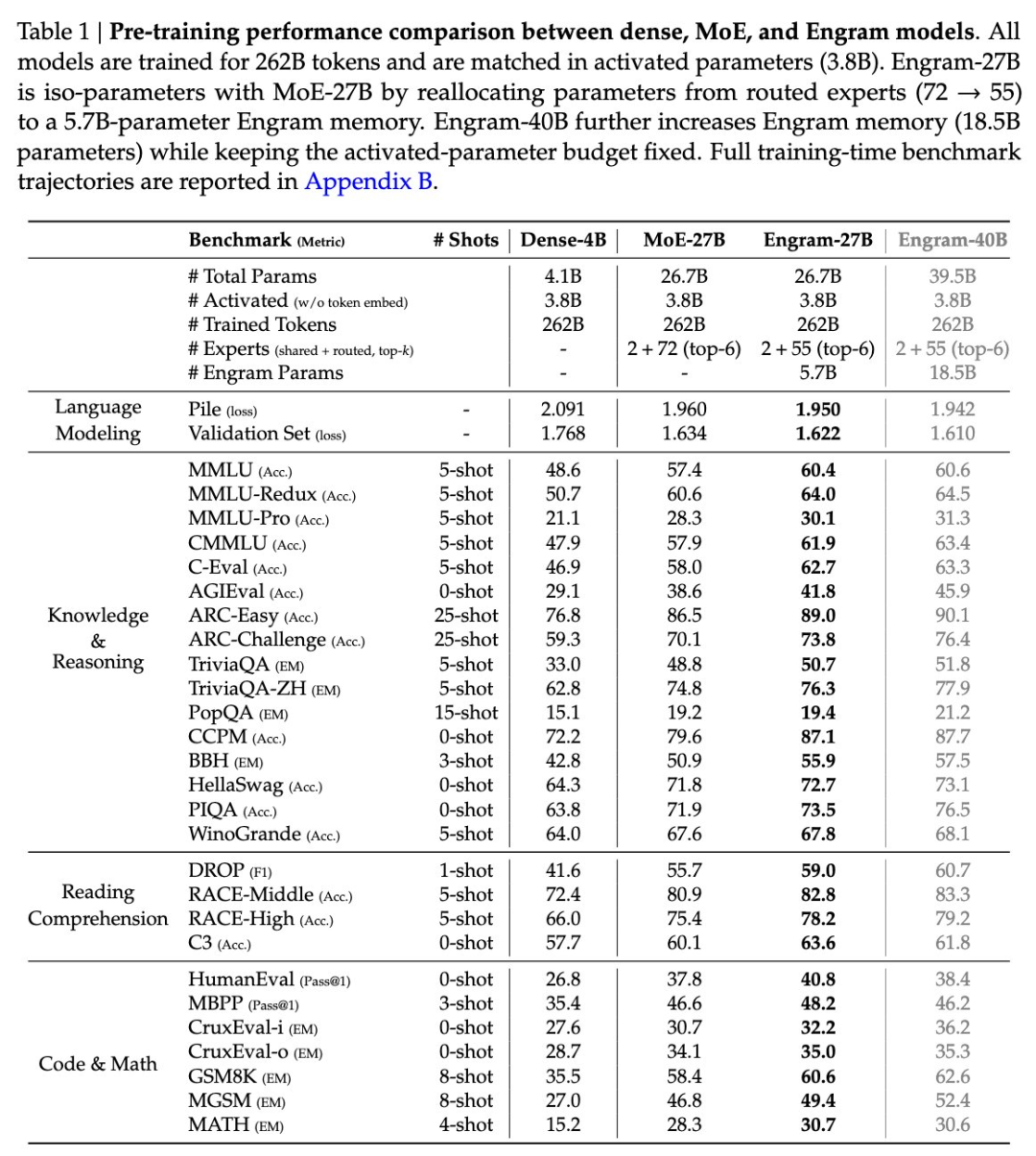
这种分工极大地优化了参数效率。在 27B 的实验模型中,Engram 模块可以占用大量的参数用于记忆,但在实际推理时,它只消耗极少的计算量(FLOPs)。
03
网友:V4 将采用这种架构
在 Reddit、X 和其他平台的相关帖子中,Engram 的技术核心受到了不少用户的肯定和技术肯定。众多网友认为这个模块的特点在于让模型架构处理“记忆模式查找”和“神经计算推理”两块职责分离,从而开启了新的稀疏性方向。
在 Reddit 平台有用户评论说:
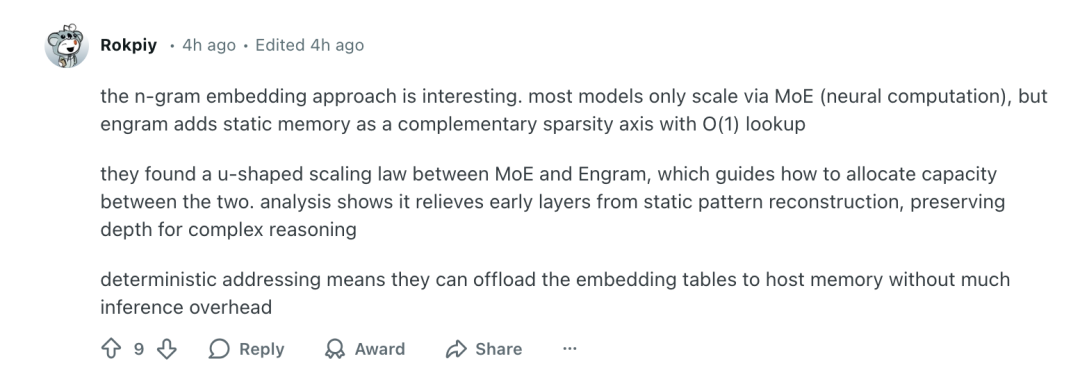
“Engram 嵌入方法很有意思。大多数模型仅通过 MoE 进行扩展,但 Engram 增加了静态记忆作为补充的稀疏性轴,查找复杂度为 O(1)。他们发现 MoE 和 Engram 之间存在 U 形缩放规律,这指导着如何在两者之间分配容量。分析表明,这减轻了早期层级静态模式重建的压力,从而保留了用于复杂推理的深度。确定性寻址意味着它们可以将嵌入表卸载到主机内存中,而不会增加太多推理开销。”
同时,有用户对这种基于 n-gram lookup 的机制表达了直观兴趣,他评论道:
即便是在不依赖 GPU 的环境下也能实现这种 O(1) 查找方式,让不少开发者对本地部署这样的大模型功能有了更实际的期待。
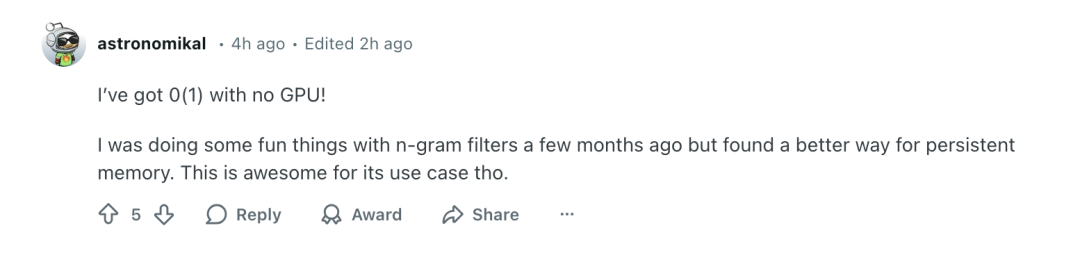
在部分技术性评论中,有人指出:
从已有技术逻辑来看,在 LLM 中加入静态记忆查找似乎是“顺理成章”的发展方向。
这类观点反映了一个重要观点:专家群体开始从纯参数扩张思维转向更“智能”的架构设计,包括查表式模块和神经网络的协同。
不少高级开发者在讨论中进一步提到,这种设计在理念上类似于对传统 NLP 技术(如 n-gram embedding)的现代化转换,结合了高效寻址机制(deterministic addressing)和神经推理模块,这种组合在纸面上看具有较高的可行性和实用性(这一点正是 Engram 的核心贡献)。
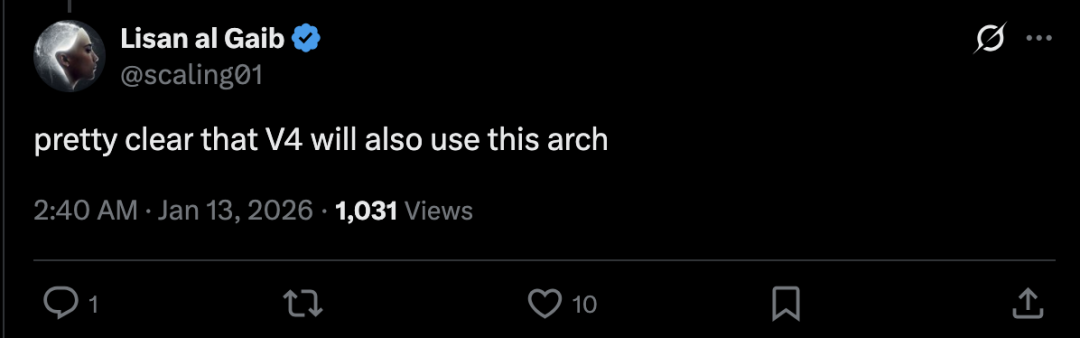
另一条社区评论指出,Engram 很可能是 DeepSeek 即将发布的 V4 模型的核心技术基础:
Engram 模块可能会成为 DeepSeek V4 的重要组成部分,并预示 DeepSeek 下一代模型会在记忆和推理协同上实现架构级提升。
在 X 平台,也有网友表达了同样的猜测,认为 V4 也将采用这种架构。
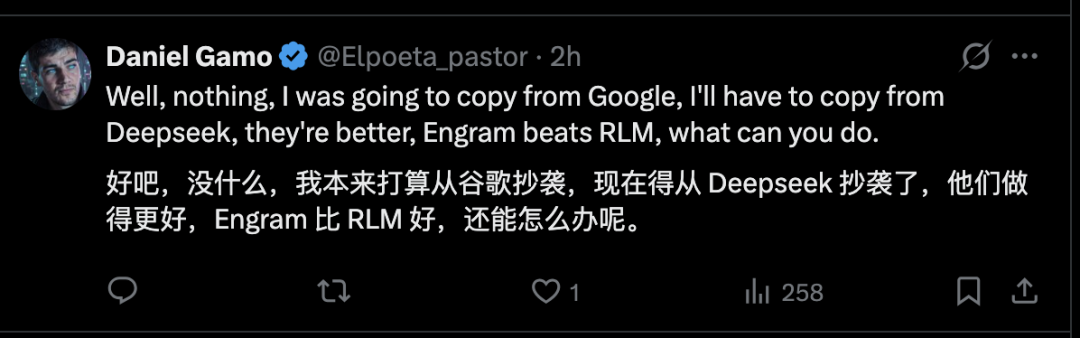
还有网友调侃,原本想抄袭下谷歌的技术,但现在要抄袭 DeepSeek 了,因为它比谷歌更好!
还有网友表示,其实 Meta 之前也有过类似想法,但用到的技术不同。

本文转自:凤凰网科技
原文地址: https://tech.ifeng.com/c/8pqe3kXUEvI
小同爱分享1 个月前
命没了还有轮回,钱没了,死都不甘心。 - 小同爱分享
小同爱分享4 个月前
疫情,就是让人抑郁,又没了感情。 - 小同爱分享