



摘要:
向来以低调和技术驱动著称的DeepSeek,自成立以来鲜少以官方身份如此高调招人。
凤凰网科技 出品
作者|姜凡
编辑|董雨晴
6月25日晚上9点35分,DeepSeek的官方公众号推送了一条招聘信息。标题叫“寻找闪亮发光的你”。不止于此,官网也同步放出了同样的信息。

文章内容并不复杂,他们在文章里称,公司正努力将所有部门的规模扩大至少一倍。7个大类、33个岗位,工作地点北京和杭州,所有岗位均接受实习。这成了DeepSeek成立以来规模最大的一次公开招聘。
2019年,还是非营利性组织的OpenAI创立了有限盈利子公司,同年获得微软10亿美元融资。这是OpenAI从理想主义实验室走向商业实体的关键转折点。这次转折,为2022年ChatGPT的发布埋下伏笔,数年后,ChatGPT成为了周活8亿的超级AI新星。
“当今人类正处于AGI的前夜。加入DeepSeek,亲历AGI的发展进程,坐在时代前排,见证一个新纪元的诞生。”而向来以低调和技术驱动著称的DeepSeek,自成立以来鲜少如此高调招人。

凤凰网科技从接近DeepSeek人士处了解到,DeepSeeK一直保持着精炼的团队构成,人员规模一直没有超过200人,其中算法占到了一半以上。“在DeepSeek内部,也是高度扁平化的,他们甚至可以一百多人共享一个技术文档,所有人都能看到谁在干什么,信息流通极其高效,创新的流通也很高效”。
深夜发文大规模扩招,让外界认为,DeepSeek正在从一家“小而精”的研究型机构,转向一家必须快速扩张的规模性组织。背后又意味着什么?

深夜招人背后
先看这次招聘的具体构成。
7个大类覆盖了从底层到应用的几乎全部技术栈。全栈开发和算法方向是最重的板块,8个岗位涉及服务端开发工程师、预训练数据工程师、AI搜索算法/架构工程师。AI核心系统研发方向则指向了超算集群研发工程师、高性能算子/通信/编译器工程师、大模型训练/推理框架工程师、高性能分布式存储工程师。
这些岗位本质上是在为更大规模的算力集群储备工程能力。运维方向包括AI算力集群性能与可靠性工程师、AI平台运维工程师。产品部门开放了AI产品经理和AI产品运营岗位。
值得关注的是几个新方向。模型数据策略产品经理/工程师这个类别下,细分出了“专业领域数据产品经理(小语种、医学法律等学科)”“AI创作数据产品经理”“情感智能数据产品经理”。这意味着DeepSeek正在有意识地构建多语言、多学科的数据壁垒,而不仅仅是堆参数。
另一个新增的“AI跨界技术人才”岗位,明确面向“具备超乎常人才能,并希望参与创造和构建AGI”的候选人开放,不设专业背景限制。DeepSeek表示将根据个人兴趣和能力把简历匹配至最适合的研究或工程团队,“不走寻常路”“在某个领域做到极致”“有创业经历”均是加分项。

还有一个细节:这次招聘专门列出了Frontier研究员岗位,聚焦持续学习、自进化与新范式研究。这不是短期工程化的岗位,而是面向更长期的技术探索。

DeepSeek在用人理念上有一个明确的表述:“从来不寻找天才”。这话听起来有些反直觉,也有些反行业共识。一家做AGI的公司说不找天才,更像是在表达一种务实的态度:不唯学历、不唯履历,看重的是候选人在某个领域有没有真正闪光的地方。
公司还强调“让新人直接承担最核心、最重要的任务”。这种用人方式在大型科技公司里并不多见,多数企业倾向于让新人从边缘任务开始,逐步证明自己。DeepSeek的选择是反过来的:直接扔进核心任务里,在实践中成长。
这次深夜招聘的直接背景,是DeepSeek刚刚完成的首轮外部融资。
6月16日,DeepSeek宣布完成成立以来的首轮外部融资,融资总额超过500亿元,这是中国AI行业迄今最大规模的单轮融资之一。
出资结构颇为特殊。创始人梁文锋个人出资约200亿元,成为本轮最大单一出资方。腾讯出资约100亿元,宁德时代体系出资约50亿元(包括宁德时代及溥泉资本),网易、京东、Monolith砺思资本、IDG资本分别出资约30亿元,正心谷投资、拾象科技分别出资约15亿元,国家人工智能产业投资基金出资约9.8亿元。
这轮融资的推进速度也值得记录。据钛媒体报道,DeepSeek最早是在2026年4月正式开启本轮融资,彼时估值约为100亿美元。4月22日,估值已攀升至超200亿美元。5月6日,有媒体报道国家集成电路产业投资基金正与DeepSeek洽谈领投,估值达到约450亿美元。到6月中旬融资落定,估值已接近590亿美元。不到三个月时间,估值翻了近六倍。
这样的融资历程,某种程度上解释了为什么DeepSeek在拿到钱之后的第一件事就是大规模招人。大约500亿元的资金注入,最直接的转化路径就是扩充团队。算力可以买,机房可以建,但没有足够的人,这些资源无法转化为真正的技术产出。
事实上,DeepSeek的招人动作并不是从这次深夜发文才开始的。过去一段时间里,它一直在通过各种渠道持续招人。
6月21日,DeepSeek旗下Harness团队负责人崔添翼在社交媒体上发起招聘。他发了一条很直接的内容:“作为新成立的部门,DeepSeek Harness组的目标远大、工作繁重,仍然非常缺人。我每天都在面试,以及各个地方张贴小广告……”Harness团队开放了三类核心岗位:Agent Harness研究员、研发工程师及产品经理,实习与全职通道同步运行,工作地点位于杭州和北京。
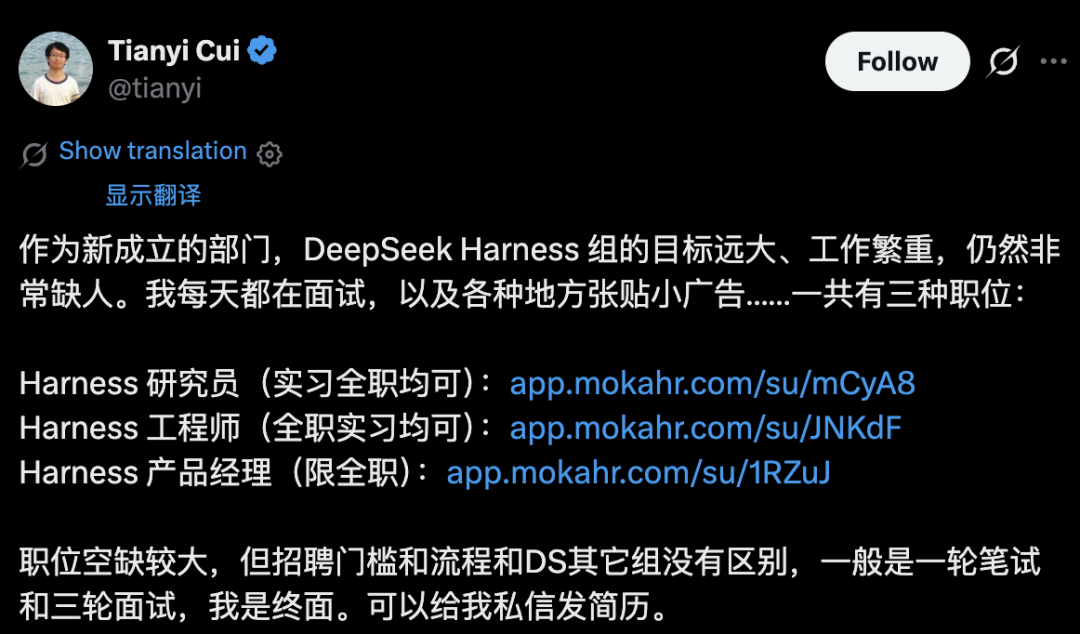
崔添翼本人是90后,与梁文锋同为浙大校友,曾在香港联合创立量化交易机构TSY Capital。今年3月正式加入DeepSeek,出任全新独立业务线Agent Harness团队负责人。DeepSeek Harness是内部专门组建的代码智能体工程团队,核心公式是“Model+Harness=Agent”。崔添翼在社交媒体上曾解释过这个团队的方向——“简单来说就是对标Claude Code,做DeepSeek Code Harness”。
值得注意的是,Harness团队的招聘海报曾因标注“良好的中文沟通能力”引发外界“不招外国人”的误读。崔添翼的回应很直接:“就像美国同类公司招人需要能用英语工作一样,DeepSeek招人需要能用中文工作。”
更早之前,今年3月DeepSeek就已经发布过一批和Agent相关的岗位,包括Agent全栈开发工程师、Agent深度学习算法研究员、Agent数据策略工程师等。这次Harness岗位的招聘,是在Agent领域的再一次加码。
从3月到6月,从零星岗位到7大类33个岗位,从社交媒体“贴小广告”到官方公众号深夜发文。DeepSeek的招聘节奏在明显加速。这肯定不是突然而至的扩招,而是一条持续了至少三个月的、逐步升级的人才争夺战线。

DeepSeek的AGI前夜
深夜发文招人这个动作本身,放在DeepSeek的发展轨迹里看,是一个值得标记的节点。
这家公司此前的形象一直是“小而精”。2023年7月依托幻方量化内部孵化落地,过去近三年始终维持着一个相对精干的团队规模。它的技术突破靠的不是人海战术,而是一小群高水平研究者在算法和工程上的深度耕耘。2025年初DeepSeek在全球范围内引发关注时,外界对它的印象就是“人不多,但很强”。
但现在不一样了。所有部门规模扩大至少一倍,意味着团队结构将发生根本性变化。从几十人到上百人,从上百人到数百人。组织规模的变化从来不只是数字的变化。沟通方式会变,决策流程会变,文化也会变。一家靠小团队默契运转的公司,如何在规模翻倍后保持同样的技术执行力和研究自由度,这是DeepSeek必须面对的管理命题。

融资结构也在传递信号。梁文锋个人出资200亿元,外部资本没有经营投票权,这套设计既拿到了钱,又没让出控制权。但钱是有成本的,资本是有预期的。
拿了约500亿元之后,DeepSeek不可能再像以前那样完全按照自己的节奏慢慢推进。它需要在更短的时间内交出更有说服力的成果。大规模招人只是第一步,接下来产品迭代的速度、商业化的路径、技术突破的节奏,都会被放到更紧迫的时间表里。
DeepSeek在招聘公告里说“人类正处于AGI的前夜”。这句话放在任何一个AI公司的宣传语里都不奇怪,但放在DeepSeek身上,多少有些分量。这家公司过去很少用这种宏大叙事来包装自己,它更习惯用论文和开源模型说话。深夜发文招人,也许意味着它判断技术竞争的窗口期正在收窄,规模本身正在成为竞争力的一部分。
从“不融资、不上市、不商业化”到完成约500亿元首轮融资,从几十人的精干团队到所有部门规模翻倍,DeepSeek正在经历它成立以来最大的一次转身。深夜发文招人只是这个转身过程中一个具体的、可被观察的瞬间。这个瞬间的背后,是一家曾经以“小而强”为标签的公司,正在主动选择成为一个“大而强”的组织。
这一步迈得是否勇敢,最终要看它能不能在规模扩张的同时,守住那个让它走到今天的东西。
本文转自:凤凰网科技
原文地址: https://tech.ifeng.com/c/8uGjzPiyNfD
小同爱分享1 个月前
命没了还有轮回,钱没了,死都不甘心。 - 小同爱分享
小同爱分享4 个月前
疫情,就是让人抑郁,又没了感情。 - 小同爱分享